1. Model Representation / Cost function
아래 내용은 Andrew Ng 교수님의 강의와 자료를 기반으로 학습한 내용을 정리하여 작성하였습니다.
개인의 학습 내용이기에 잘못 해석 및 이해하고 있는 부분도 있을 수 있으니, 다양한 자료를 기반으로 참고하시는 걸 추천드립니다.
Machine Learning 중 Supervised Learning에서 가장 기초적으로 다뤄지는 내용이 Linear regression(선형 회귀)입니다.
제 개인적인 의견으로 Linear Regression은 모델표현이 쉽고 단순하며 Cost function과 Gradient descent 등을 이해하기 쉽기 때문이라고 생각됩니다.
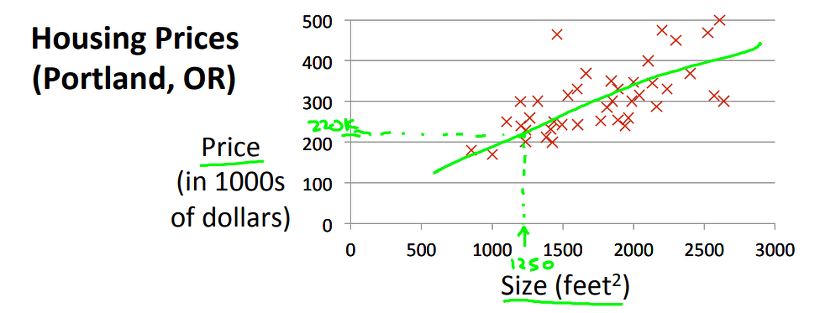
위의 그래프를 보시면, Portland의 집 크기에 따른 가격 Data를 표현한 그래프입니다. 위 Data들을 보고 친구가 만약, 1250 feet^2의 집을 사고 싶다고 한다면 여러분은 얼마라고 예측해서 대답 할 수 있나요? 대부분의 사람들이 위의 Data들을 표현할 수 있는 Model을 찾게 될 것이고, 위 그림과 같이 하나의 직선을 그어서 예측할 수 있을 것입니다. 그 후 친구에게 1250 feet^2은 22만 달러 정도 할 거라고 말해 줄 수 있겠죠.
위 과정이 Data들을 표현할 수 있는 Model을 선정하는 것, 즉 Data들을 표현할 수 있는 Algorithm을 선정하는 것인데요,.
Supervised Learning 중 Regression 이렇게 data set(right answer)가 주어져 있고, 이를 기반으로 값을 예측하는 과정을 말합니다.
용어 정리
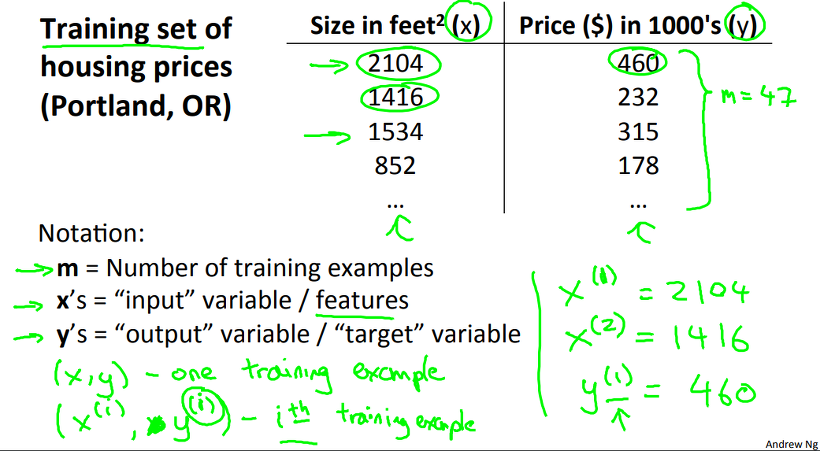
먼저, 본격적으로 시작하기 전에 사용하는 용어를 정리해 보도록 하죠, 위에서 예시로 든 Data들을 사용하여 살펴보면,
m : 학습 데이터의 숫자
x’s : 입력 변수 또는 feature
y’s : 출력 변수 또는 feature
라고 표현하고, (x, y)를 하나의 학습 데이터로 표현하며 (x(i), y(i)) 을 i 번째의 학습 입/출력 데이터를 표현합니다. 위의 그림과 같이 x(1)은 첫 번째 학습 데이터 중 입력 변수를 말함으로 x(1) 은 2104 이며, 그에 맞는 출력 변수, 결과 값은 y(1), 460 이 되죠.
어떻게 표현할 것 인가?
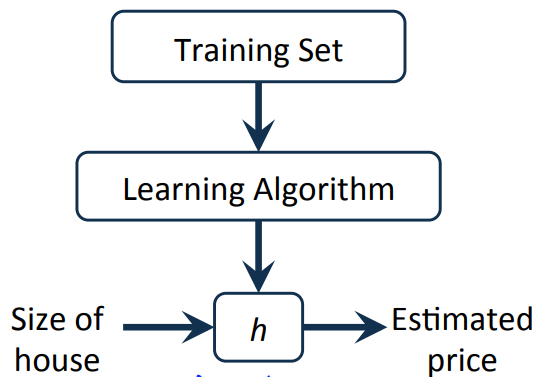
그럼 가지고 있는 Data들을 이용해서 어떻게 표현을 할 것인가? Machine Learning을 할 것인가에 대해 위 그림으로 알아보면, Training Set(학습 데이터)들을 가지고 위에서 선정한 모델, 즉 직선의 방정식을 Learning Algorithm으로 선택할 수 있고, 학습된 부분을 h(hypothesis, 가설) 이라고 말할 수 있습니다. 그 이후 입력된 집의 크기에 대해 예측된 가격을 구할 수 있죠, 이 때 hypothesis는 error가 최소인 모델이여야 할 것입니다..
Cost function (비용함수)

그럼 위에서 직선의 방정식을 Learning Algorithm으로 선정하였고, 위와 같이 표현할 수 있다고 합시다. 이 때, hypothesis의 입력에 대한 출력의 error를 최소화 하기 위한 theta 0와 theta 1을 찾아야 합니다. 어떻게 찾아야 할까요?
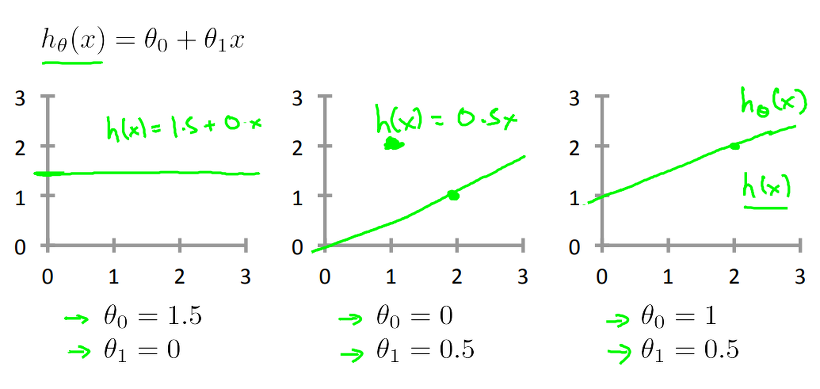
위 그림을 보면, hypothesis 모델, Linear regression을 위한 직선의 방정식은 여러 형태로 표현할 수 있습니다. theta 0와 theta 1에 따라 다양하게 표현될 수 있음을 알 수 있는데, 주어진 Training data에 대해서 위의 직선들이 모두 같은 결과를 나타내진 않을 것이며, 이 때 error을 최소화 하기 위해 theta0와 theta1을 결정하는 과정은 필수적입니다!
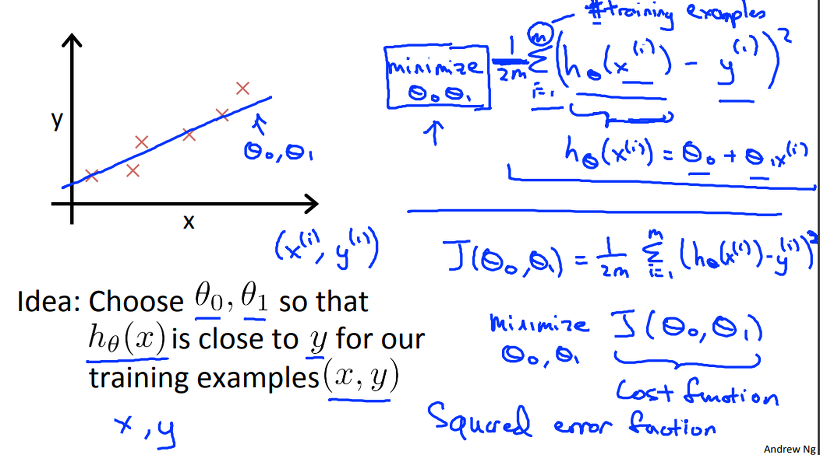
현재의 theta가 Training Set을 가장 잘 표현하고 있는가! 를 알 수 있는 방법으로 Cost function이 사용됩니다. 위 그림에서 Cost function은 **J(theta)**로 표현됩니다. 주어진 Training data들을 가장 적은 오차로 표현할 수 있는 방법을 사용하게 되며, Linear Regression은 Cost function으로 squared error function 을 사용합니다. squared error function 이란 위와 같이 최초 설정한 h(x)에 대해 Training data의 입력값을 넣었을 때 출력값과, 실제 해당 입력값에 대한 Training Data의 출력값의 차의 제곱을을 이용하는 방법입니다.
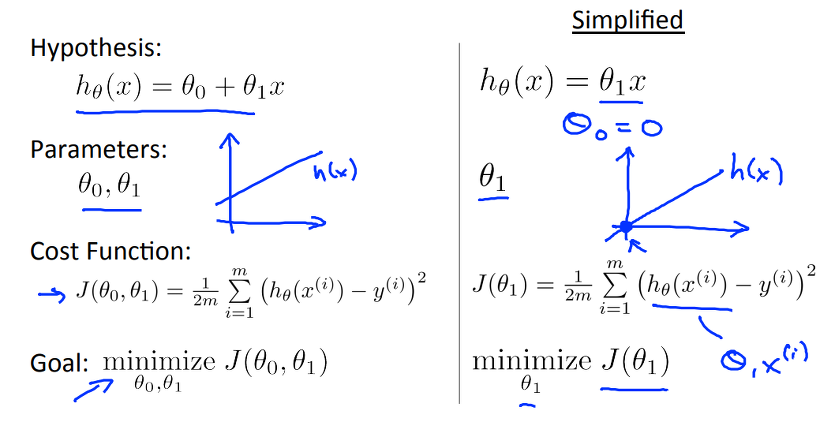
그렇다면, 전체 Training data에 대해 위와 같이 Cost function의 값을 구하고 그 값을 최소화 하면 우리가 원하는 theta0, theta1을 구할 수 있음을 알 수 있습니다.
다양한 h(x)에 대해서 Cost function의 그래프가 어떻게 표현되는지 살펴보시죠.
예를 들어 m = 3이며, (x,y) = {(1,1), (2,2), (3,3)} 이라 하고, J는 squared error function 을 사용한다고 하면,
(1) h(x) = x , (theta0 = 0, theta1 = 1)
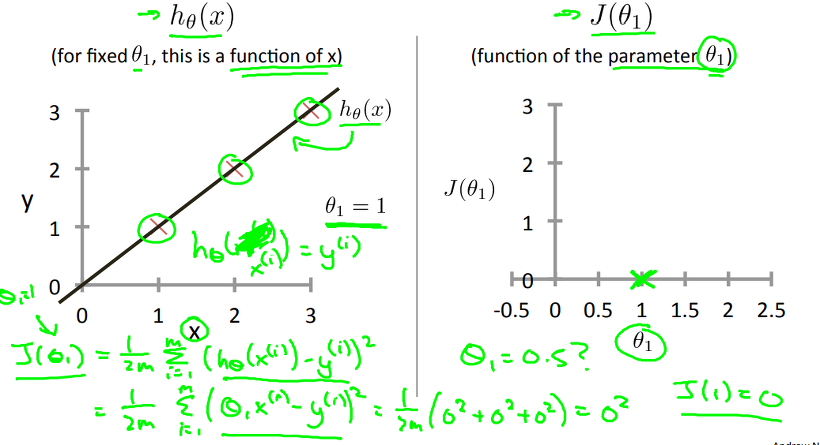
주어진 Training data에 대해 J를 구하면, theta 1 = 1일 때, J는 0.
(2) h(x) = 0.5x (theta0 = 0, theta1 = 0.5)
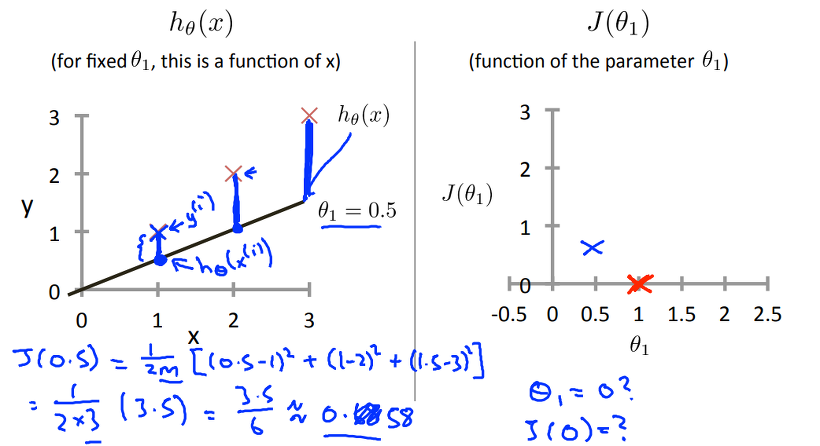
주어진 Training data에 대해 J를 구하면, theta 1 = 0.5일 때, J는 0.5.
위 처럼 theta = 0인 상태에서, theta1의 값을 계속 변경하게 되면 J(theta1)에 대해서 아래와 같은 그래프가 그려짐을 알 수 있습니다.
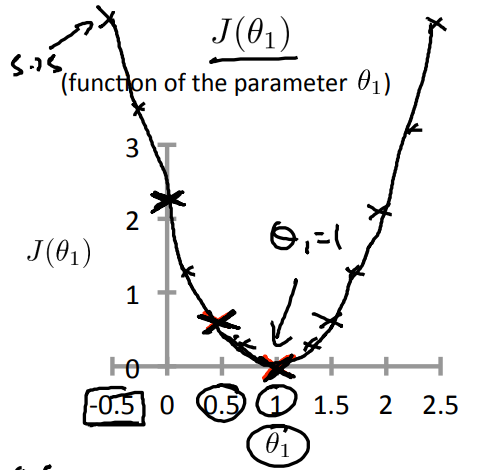
위 그래프에서 minimize J(theta1)은 theta1이 1 일 때 임을 매우 쉽게 확인할 수 있습니다.
그럼, 위의 예시로 나온 집 크기에 따른 가격 Training data를 이용해서 theta0와 theta1을 구하는 과정을 살펴보도록 하겠습니다.
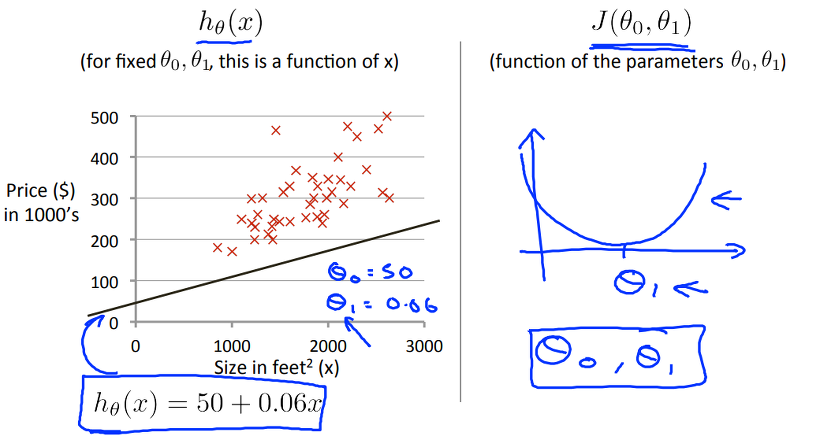
만약, h(x) = theta0 + theta1 * x 에 대해 theta0 = 50, theta1 = 0.06이라 가정하면 위와 같은 hypothesis를 구할 수 있습니다. 그에 대한 J(theta0, theta1)값은 오른쪽에 표시된 그래프인데, 유의할 점은 theta0는 고려하지 않은 theta1에 대한 J의 그래프 란 것입니다. 이렇게 보면 굉장히 단순하고 최소값을 찾기 쉽지만, theta0까지 함께 고려한다면, J의 그래프는 아래와 같이 곡면(?)이 될 수 있습니다. 아래와 같은 형태를 Contour plots 또는 Contour figure 라고도 합니다.
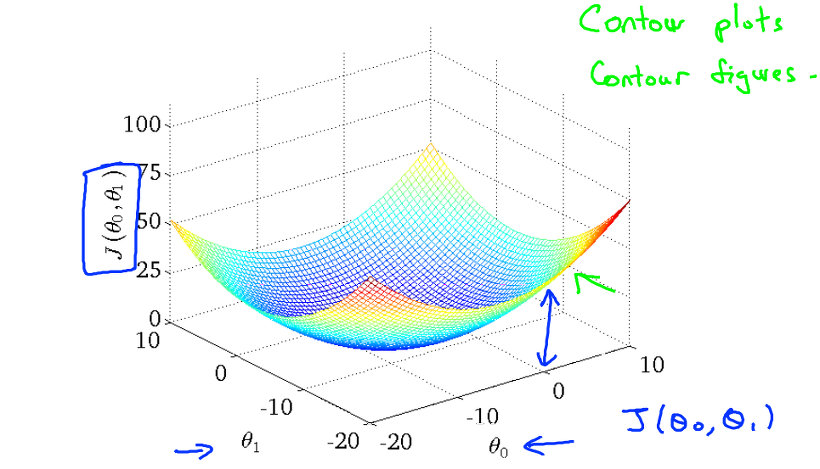
그럼 이제 Cost function으로 구한 J값을 최소화 하기 위해 어떤 과정이 일어나는 알아보시죠.
최초 무작위로 선정한 theta0, theta1에 대한 hypothesis와 J가 아래와 같을 때, J를 최소화 하기 위해선, J가 Contour plot의 중앙, 즉 등고선의 중심으로 이동해야 한다. 총 4개의 과정으로 J가 감소해가면서, hypothesis가 어떻게 변하는지 확인 할 수 있습니다.
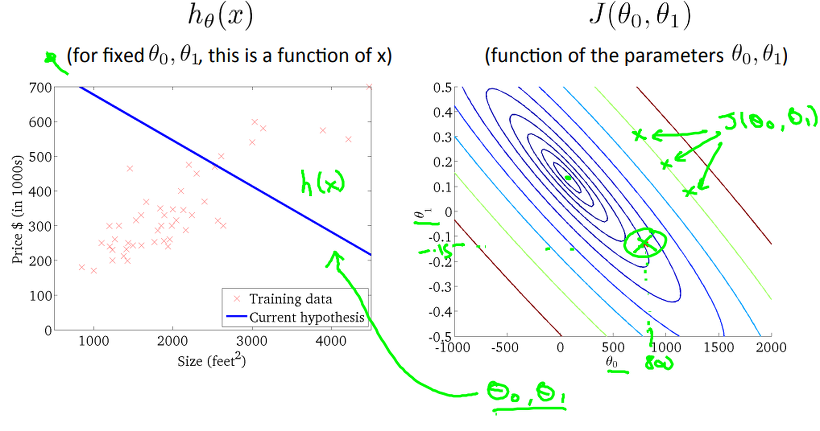
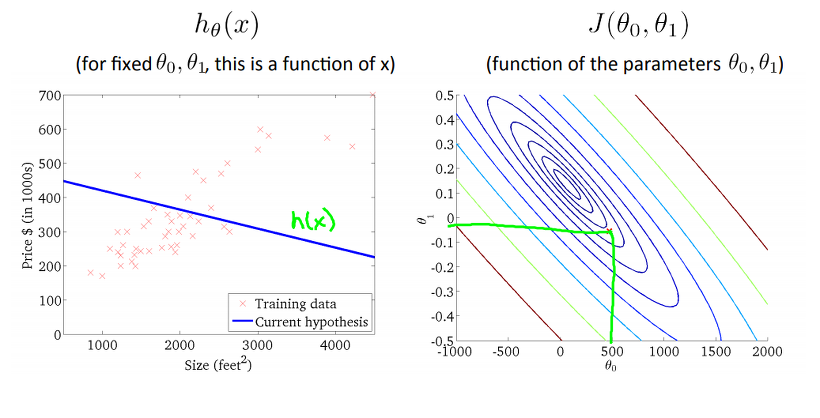
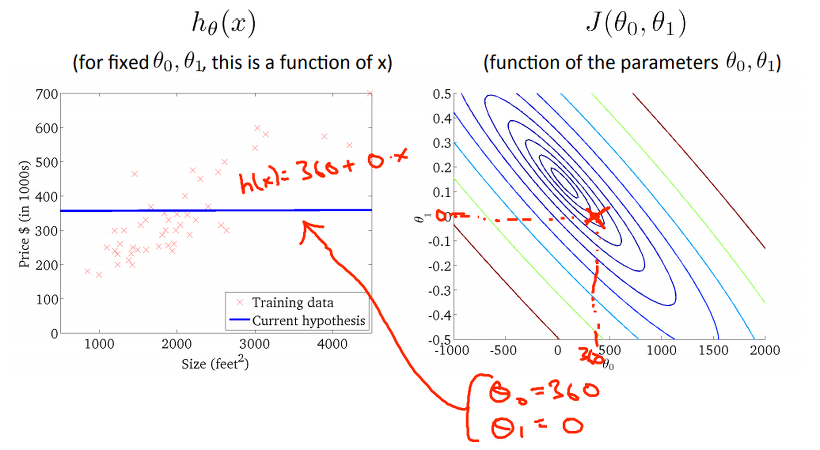
우리가 원하는 모습은 바로 위의 그래프처럼 입력된 Training Data에 대한 error가 최소화 될 수 있는 직선의 방정식, 즉 hypothesis를 구하는 것임을 알 수 있다! 위에서 Cost function을 이용해서 J를 구하고, theta0, theta1에 변화에 따라 J가 감소되는 것 까진 확인하였는데, 그럼 어떻게 J를 감소시켜야 할지, theta0와 theta1은 어떻게 결정해야 할지를 알아봐야 합니다. 그 내용은 다음 글에서 계속 설명 드리겠습니다.